When working on ULTRA's genetic programming engine, one apparently small detail turned into an interesting exploration of modern C++ design and performance trade-offs: how to iterate efficiently over active genes (exons).
At first glance, this looks trivial. In practice, it touches iterator semantics, ranges, container choice, memory behaviour and even differences between standard library implementations.
Iterating only over active genes
A genetic programming individual contains many genes, but only a subset is active, the exons that contribute to the final program output.
The requirements are:
- iterate only over active genes;
- discover active genes dynamically by following dependencies;
- expose a clean, idiomatic C++ interface;
- integrate with C++20 ranges;
- avoid materialising the exon set eagerly;
- remain efficient across compilers and standard libraries.
The traversal naturally resembles a dependency-driven graph walk, starting from the output locus and exploring referenced loci.
Iterator semantics
The traversal is inherently single-pass:
- the next exon depends on what was discovered so far;
- the internal frontier changes at each step;
- dereferencing depends on mutable iterator state.
This immediately rules out forward or bidirectional iterators.
The correct abstraction is a C++20 input iterator with a sentinel, which leads naturally to a view-based design:
exon_view;const_exon_view.
These are lightweight, non-owning views that expose exon traversal as a range, without leaking iterator internals.
This also avoids "fake end iterators" and makes termination a semantic property (no loci left to explore), not a syntactic one.
The frontier, what container should we use?
At the heart of the iterator lies a frontier of loci yet to be explored. The frontier must:
- return the next locus deterministically;
- suppress duplicates;
- support frequent insertions and removals.
Several implementations were tested (see the source code).
std::set
Using an ordered set gives:
- automatic duplicate suppression;
- deterministic ordering;
- logarithmic operations.
The initial implementation used:
std::set<ultra::locus, std::greater<ultra::locus>>
Surprisingly often, this simple approach performed very well.
basic_exon_iterator &operator++()
{
if (!loci_.empty())
{
const auto &g(operator*()); // must be evaluated before erase()
// Erasing first makes the tree shallower and reduces comparison work
// during subsequent insertions: we remove the comparison hotspot and
// the erased element was the one most likely to be compared against.
loci_.erase(loci_.begin());
for (const auto &a : g.args)
if (a.index() == d_address)
loci_.insert(g.locus_of_argument(a));
}
return *this;
}
std::set with .extract
One of the explored optimisations was a variant based on node extraction:
auto node = loci_.extract(loci_.begin());
node.value() = new_locus;
loci_.insert(std::move(node));
The motivation was straightforward:
- reuse an existing tree node instead of allocating a new one;
- reduce allocator traffic;
- avoid destroying and re-creating nodes in tight iterator increments.
At first glance, this seems like a perfect fit for a dependency-driven traversal where one locus is replaced by one or more new ones.
This variant optimised memory management, not algorithmic structure.
Despite being correct, measurements showed that the .extract variant was consistently slower than the simpler approach.
Saving an allocation simply did not move the needle. Even when reusing a node, reinsertion still performs full tree traversal; the most expensive work remains exactly the same.
Node extraction is also not free, it introduces an additional abstraction layer (node handles are heavier than raw pointers and reinsertion involves extra bookkeeping).
In a hot inner loop, these costs can outweigh the saved allocation.
std::priority_queue
A heap-based frontier was also tested, with explicit duplicate handling:
- push discovered loci;
- pop until a new value is found.
This reduces pointer chasing and improves locality, but requires careful duplicate skipping.
std::flat_set
flat_set behaves very much like a priority queue with deduplication baked in, which is conceptually exactly what we need.
It's a good fit for the problem but doesn't outperform other options.
Flat approaches (vectors / matrix)
Several flat representations were tried:
matrix<bool>(implemented viastd::vector<bool>);matrix<char>(a custom matrix wrapper overstd::vector<char>).
All performed orders of magnitude worse, despite good locality.
A key micro-optimisation: erase first, then insert
One small but important discovery was that erasing the current locus before inserting newly discovered ones consistently improved performance for ordered containers.
The reason is structural:
- the erased element is a comparison hotspot;
- removing it first reduces tree height;
- subsequent insertions do less work.
This optimisation is subtle, measurable and now explicitly documented in the code to prevent accidental regression.
For further discussion see the specific post.
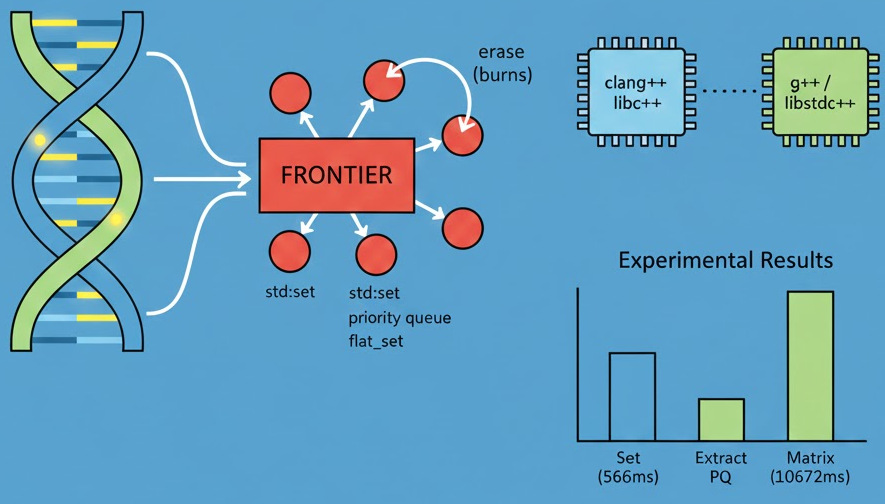
Experimental results
On a representative benchmark (clang++ / libc++):
Default iterator ~566 ms
Set extract iterator ~684 ms
Priority queue ~644 ms
matrix<char> ~10672 ms
Flat set ~645 ms
Two observations stand out:
std::setseems better butstd::flat_setandstd::priority_queueare very close in practice;- no single container dominates across all implementations and compilers.
Compiler-dependent results
An unexpected but instructive outcome emerged:
clang++/libc++favouredstd::set;g++/libstdc++favouredstd::priority_queue.
This reflects real differences in: tree node layout, heap algorithms, comparator inlining and branch prediction strategies.
In other words, we were benchmarking standard library implementations, not abstract data structures.
Clarity over micro-optimisation
Given that:
- both implementations are asymptotically optimal;
- both are close in performance;
- results depend on the STL implementation;
std::setprovides simpler semantics (ordering + deduplication)
the final decision was to keep the std::set-based frontier, with:
- explicit iterator and range semantics;
- clear documentation of invariants;
- comments explaining performance-sensitive choices.
This keeps the code readable, maintainable and portable.
Lessons learned
- Input iterators are underrated. Many traversals are naturally single-pass; modelling them honestly avoids lying to the type system.
- Benchmarks matter more than intuition. Several "obvious" optimisations were slower in practice.
- Don't "normalise" performance across compilers/libraries.
libc++andlibstdc++make different trade-offs. Portable code must accept that. Clarity wins over a 10% performance difference. - Sometimes the best optimisation is a comment. When the standard does not expose a tuning knob, documenting the reasoning is the right solution.